SDTP是在大脑中发现的神经元之间权重连接的更新规则,他的目标非常的清晰就是如果两个神经元的发放在时间上离的远近,他们之间的绑定关系就越紧密,一般就反映到激活权重越大上。我从文献[1]中盗了个图,如下:
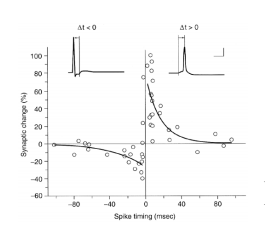
我们可以看到,如果一个神经元A的激活在另一个神经元B的激活之后很快就发生,时间差小于5ms时,B到A的连接权重就会增加约70%,而相反A到B的连接权重就会衰减20%。什么意思?通俗的说,就是当A和B先后激活时,具备紧密先后关系的双方会加强联系,而具备相反关系的,就会渐行渐远,这样的规则带来了什么样的结果呢?那就是具备时间上和空间上同时性或连续性的事件之间建立带有次序关系的联系。从这个角度,也可以想象到神经元之间往往建立的是单向的加强联系,如果A到B不断增强,那么B到A就不断减弱,而如果是同时发生,一般两者会不好不坏,而他们的共同下游则与他们之间形成了更加紧密的联系, 从而两者变成了同级,并具备了间接关系。
经过前面的表述,你会发现,一个简单的小规则,在整个自组织的过程中,形成了十分复杂的组织结构,建立起来的组织结构具备了记忆、组合和特征发现的能力,这些属性都是今天各路研究者分开研究的独立项目,但可能在脑中就同一套算法在不同的输入状态下的不同结果。
当前的研究综述经常提到一个结论,就是人脑在不同的部分、不同的时期都具备不同的目标函数[2],如果将大脑的权重看成是可训练的参数,那么STDP规则本身是否可以直接推导出全脑统一的目标函数,对此Youshua Bengio研究团队做出了努力[1]。
但接下来的问题就变成了实验,应用这个目标函数,我们能否得出像大脑一样的结果,我们如果运用这个目标函数进行实时在线训练?还是单纯的使用自组织的方式,应用STDP规则,抛弃全局目标函数这个思路?
欧脑计划想走的是自组织的道路,北美研究圈们主要是训练的道路,目前来看训练的道路取得了暂时的领先,但这种领先仍然是在有监督学习相关的AI任务上,面对更加高级的AI任务,现在的有监督学习方案仍然有很多缺陷:
一、依赖大量有标签数据
二、无法进行小样本学习、有效的迁移学习
三、无法进行有效的归纳(聚类)、推理
四、对无监督学习自特征发现的利用远远不够
这些问题的解决,对于更加高级的AI任务将有重大的作用。
我的观点是:无论自组织方式还是寻找到恰当的目标函数的方式,进行无监督学习都是需要进行的一步,最近的研究风向又倒回到了有监督学习,尤其是几个成功的深度网络,在采用了数据增强、ReLU、dropout等等技术手段后,可以直接抛弃无监督预训练。
无监督预训练最重要的价值就是找出大量的无法标签的特征,这些特征的发现和完美表示能力,是构成更加高级智能的基石。很多时候,我们要跳出训练的思维,实在不行,你们就手动指定参数吧,就像Chris Eliasmith干的那样[3]。
[1] Y. Bengio, T. Mesnard, A. Fischer, S. Zhang. An objective function for STDP. http://arxiv.org/pdf/1509.05936
[2] Adam Marblestone, Greg Wayne, Konrad Kording. Towards an integration of deep learning and neuroscience. https://arxiv.org/abs/1606.03813
[3] Chris Eliasmith. How to Build a Brain: A Neural Architecture for Biological Cognition