本文翻译了DeepMind的最新研究成果的第一部分,可以当做是introduction部分,借鉴神经科学成果,解决了一个通用人工智能领域持续学习所面临的关键性难题。
实现通用智能需要智能代理能够学习和记住许多不同的任务[1]。在现实世界中这很困难:任务的顺序并不会显式地标注出来,任务之间可能会不可预期地切换,单一任务可能在很长的一段时间内都不会复现。因而,智能代理必须具备持续学习的能力:也就是学习连贯的任务而不会忘记如何执行之前训练过的任务的能力。
持续学习对人工神经网络是一个特别大的挑战,因为与当前任务(比如任务B)相关的知识被合并掉,关于先前任务(比如任务A)的知识会突然地丢失。这个现象术语叫灾难性遗忘(catastrophic forgetting)[2-6],一般会发生在神经网络在多个任务上进行按序训练的时候,比如对任务A很重要的神经网络的权重正好满足任务B的目标时。然而近来机器学习的进步,尤其是深度神经网络的进步对各个领域已经产生了广泛的有利影响(如文献7和8),但连续学习领域的研究却停滞不前。当前的方法主要是通过确保来自各个任务的数据在训练中都可以同时获得。通过在学习过程中对来自多任务的数据进行交叉操作,其实遗忘并不会发生,因为神经网络的权重能够对所有任务上的表现进行联合优化,但这个方法通常指的是多任务学习范式-深度学习技术,已经被成功地应用在训练单一智能体玩多种Atari游戏[9,10]。如果任务按序呈现的话,只能在数据存储在事件记忆系统并在训练的过程中对网络进行回放时,才能采用这种多任务学习技术。这种方法(通常也叫系统级巩固[4, 5])面对学习大量任务时并不实用的,因为按照我们的设定,它应该需要与任务数量成比例的存储数量。相关算法的确实成为通用智能开发的关键障碍。
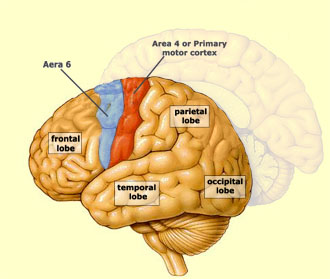
与人工神经网络形式鲜明对比的是人类和其他动物似乎能够以连续的方式学习[11]。最近的证据提示哺乳动物的大脑可能会通过大脑皮层回路来保护先前获得的知识,从而避免灾难性遗忘[11-14]。当小鼠需要一个新技能的时候,一定比例的突触就会增强,表现为单一神经元的树突棘数量的增加[13]。至关重要的是,即使进行了后续的其他任务的学习,这些增加了的树突棘能够得到保持,以便几个月后相关能力仍然得到保留。当这些树突棘被选择性“擦除”后,相关的技能就会被遗忘[11,12]。这表明对这些增强的突触的保护对于任务能力的保留至关重要。这些实验发现与诸如瀑布模型[15, 16]这样的神经生物学模型提示我们大脑皮层中的持续学习依赖于任务相关突触的巩固,知识能够长久地编码得益于让一部分突触降低可塑性从而在相当长的时间范围内变得稳定。
本次工作将展示任务相关突触巩固为人工智能的持续学习问题提供了独特的解决方案。我们为人工智能神经网络开发了一种类似于突触巩固的算法,称之为可塑权重巩固(elastic weight consolidation,EWC)。这个算法会针对那些对特定任务特别重要的特定权重降低学习率。也会展示EWC如何应用在监督学习和强化学习问题中,在不会遗忘旧任务的情况下,按次序地训练多个任务,并与之前的深度学习技术进行对比。