本文对论文《world Models》的前半部分进行了翻译,看过前半部分基本就了解结构了,我个人认为Schmidhuber还是一如既往地喜欢把小东西往宏大了说,当然也多亏了他起的题目,很多人对世界模型产生了浓厚的兴趣。但本文的确不能说在世界模型方面有了飞跃的进步,只是将隐变量配合LSTM当作了世界模型,所以我不打算翻译后半部分了。虽然现在大家对于时序问题还没有太好的办法,很多时候不得不靠LSTM,但LSTM绝对不是未来。
世界模型 World Models
David Ha, Jurgen Schmidhuber
摘要
我们研究在流行的强化学习环境中构建生成神经网络。以监督的方式可以快速训练我们的世界模型学会环境的压缩空间和时间表征。将从世界模型中抽取的特征作为智能体的输入,我们能训练出一个非常紧凑简单的指定任务解决策略。我们也能训练智能体完全沉浸在自己的幻觉中基于它的世界模型做梦,并将策略迁移回实际环境中。
1. 介绍
人类会基于其有限的感觉输入构建关于世界的心灵模型。我们所作的决策和采取的行动都是基于这个内在模型的。系统动力学之父Jay Wright Forrester这样描述心灵模型:环绕我们的世界景象不过是承载于我们脑中的模型而已。无人能在脑中想象整个世界,政府或国家。他只有筛选过的概念、概念间的关系和使用它们去表征真实系统(Forrester, 1971)。

为了处理每时每刻都流入我们生活的海量信息,大脑要学会抽象表征信息的空间和时间特性。由此我们可以观察一个场景,记住一个抽象的描述(Cheang & Tsao, 2017; Quiroga et al., 2005)。各项证据表明我们在任何时刻的感知都在大脑基于内在模型对未来的预测的管控之下(Nortmann et al., 2015; Gerrit et al., 2013)。理解脑中预测模型的一种方式是,模型不一定只是预测未来,而是在给定当前运动预测未来的感受数据(Keller et al., 2012; Leinweber et al., 2017)。我们可以本能地在预测模型上进行推演,一旦发生危险时,可以快速反应(Mobbs et al., 2015),而不需要有意识地进行行动计划。

以棒球为例。击球手只有毫秒级的时间来决定如何挥动球棒,时间要短于它大脑接受到相关视觉信号的时间。我们之所以有这种击打速度为100mph棒球的能力,就是因为我们可以本能地预测球将在何时到达哪里。对于专业选手来说,这一切都发生在潜意识。按照内在模型的预测肌肉可以反射性地在恰当时间和位置挥动球棒(Gerrit et al., 2013)。他们可以迅速地根据自己对未来的预测采取行动,而不需要有意识地推演未来可能的情景来制定运动计划(Hirshon, 2013)。

许多强化学习问题(Kaelbling et al., 1996; Sutton & Barto, 1998; Wiering & van Otterlo, 2012)中,人造智能体也会受益于对过去和现在状态的良好表征,以及拥有一个较好的未来预测模型 (Werbos, 1987; Silver, 2017),尤其是诸如RNN这样具有通用目的的强大的预测模型(Schmidhuber, 1990a;b; 1991a;译者注:又犯病了)。
大型RNN是高强度表达模型,可以学会数据丰富的空间和时间表征。然而很多模型无关的RL方法却常常使用参数很少的小神经网络。RL算法也经常面临授信瓶颈问题,这又使得传统RL算法难以应用大规模的模型,因而导致实践中都采用较小的网络,进行更快的迭代以便在训练中获得一个好的策略。
理想地,我们希望能有效地训练基于大型RNN的智能体。反向传播算法(Linnainmaa, 1970; Kelley, 1960; Werbos, 1982)可以用来有效地训练大型神经网络。本文中,我们训练一个大型网络来处理RL任务,将智能体分开成一个大型世界模型和一个小型控制器模型。我们首先训练一个大型神经网络以无监督的方式来学习智能体周围环境的世界模型,然后训练小型控制器模型利用该世界模型完成任务。小型控制器让训练算法更加关注于小搜索空间内的授信问题,而不会牺牲大型世界模型的规模和表达能力。我们发现智能体透过世界模型看世界,可以学到非常简洁的策略来完成任务。
当前有大量的基于模型的强化学习研究,但本文并不是一个综述。本文的目标是从1990-2015的一系列论文中提炼几个关键概念,主要是关于基于RNN的世界模型和控制器(Schmidhuber, 1990a;b; 1991a; 1990c; 2015a)。我们也会讨论一些其他的工作,都有类似的想法,即学习世界模型和训练智能体利用该模型。
本文提出一个简单的框架,实验性地展示这些论文中的一些关键概念,同时针对不同RL环境应用这些概念提出了一些建议。我们在“学会思考:结合RL控制器和RNN世界模型的算法信息理论”一文中描述我们的方法论和实验时也应用了类似的术语和符号。
2 智能体模型
受认知系统启发,我们提出了一个简单的模型。模型中,智能体拥有一个视觉感受器组件,可以看到一小部分表征编码,还有一个记忆组件基于历史信息预测未来的编码,最后还有一个决策组件只基于视觉和记忆组件创建的表征做出动作选择。
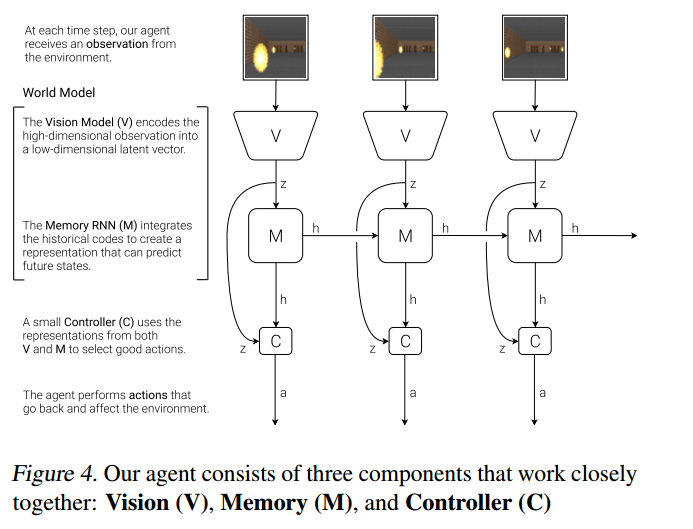
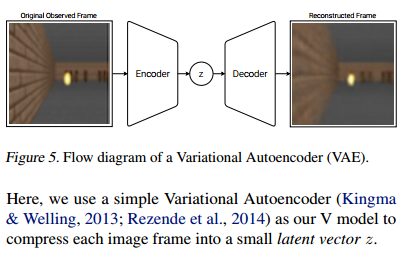
2.1 VAE模型 (模型V)
每个时间步上环境提供的观察数据都是非常高维的。通常是一幅2维图像,属于视频序列的一部分。模型V的角色是学会输入帧的抽象压缩表征。我们使用一个简单的变分自编码器(Kingma & Welling, 2013; Rezende et al., 2014)作为我们的模型V,将每幅图像都转成一个很小的隐变量向量z。
2.2 MDN-RNN模型(模型M)
模型V的作用是压缩每一帧的输入,但我们还需要压缩跨越时间的所有帧输入。所以模型M的目的是预测未来。模型M是预测模型V的隐变量z未来的输出。由于现实环境的诸多复杂随机性,我们训练RNN的输出为一个概率密度函数p(z),而不是z的确定预测。
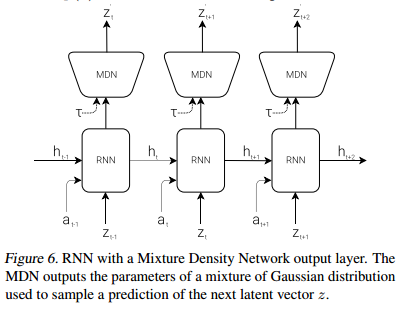
我们的方法中,p(z)逼近于一个混合高斯分布,RNN被训练成在给定当前和过去信息的情况下,输出下一帧隐变量\(z_{t+1}\)的概率分布。特别低,RNN建模了\(P(z_{t+1}|a_t,z_t,h_t)\),其中\(a_t\)为时刻t采取的动作,\(h_t\)为时刻上RNN的隐藏状态。采样时,我们调整一个温度参数\(\tau\)来控制模型不确定性,诸如(Ha & Eck, 2017)中做的,我们发现调整\(\tau\)对于后面训练控制器非常有用。这个方法可以看作是结合了RNN(MDN-RNN)(Graves, 2013; Ha, 2017a)的混合密度网络(Mixture Density Network, Bishop, 1994),被应用在序列生成问题,比如生成手写体(Graves, 2013)和简笔画(Ha & Eck, 2017)。

2.3. 控制器模型(模型C)
控制器模型负责在一看到环境时就要决定采取什么样的动作才能最大化智能体的预期收益。实验中,我们故意让模型C尽量的小,并和V、M分离开训练,这样可以把智能体的复杂性都放到世界模型中(模型V和模型M)。
模型C就是一个简单的一层线性模型,将\(z_t\)和\(h_t\)映射成每个时间步的动作:
\(a_t=W_c[z_th_t]+b_c (1)
\)
该线性模型,\(W_c\)和\(b_c\)分别是权重矩阵和偏移向量,将串联到一起的\([z_th_t]\)映射成动作向量\(a_t\)。
2.4 将模型V, M和C放在一起
下面这个流程图说明了模型V、M和C是如何与环境交互的。
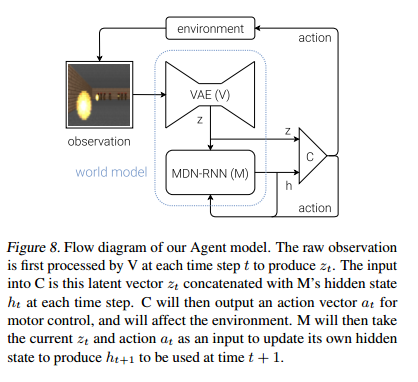
下面是我们智能体模型在openAI Gym(Brockman et al., 2016)环境下的伪代码:

在给定的控制器C上运行这个函数会在一轮次后返回一个累计奖励值。控制器C的最小化设计带来了极大的现实好处。深度学习的优势是可以高效地训练大型复杂模型,而我们只需要定义一个精心设计的可微分损失函数。模型V和M的设计都使其可以在现在GPU加速器上借助反向传播算法进行高效训练,所以我们希望将模型的大部分复杂性包括大部分模型参数留在V和M中。线性模型C的参数数量则是相对而言是非常小的。这种选择令我们可以探索更多C的训练方式——比如,使用进化策略(evolution strategies, ES, Rechenberg, 1973; Schwefel, 1977)来解决更多面临授信困难的富有挑战性的RL任务。
为了优化C的参数,我们选择了协方差矩阵适应进化策略(Covariance Matrix Adaptation Evolution Strategy, CMA-ES; Hansen, 2016; Hansen & Ostermeier, 2001)作为优化算法,原因是这个算法对高达几千个参数的解空间效果很好。参数的进化是在单台多CPU的机器上并行执行多轮环境rollout(轮次)。对于模型、训练过程和环境的更多特定信息,可以参见附录部分。
3. 赛车实验
【翻译略】
4. VizDoom实验
【翻译略】
5. 迭代训练过程
【翻译略】
6. 相关工作
【翻译略】
7. 讨论
【翻译略】