本文对Deepmind最新成果GQN论文的主要部分进行了翻译
场景的神经表征与渲染 Neural scene representation and rendering
S. M. Ali Eslami, Danilo Jimenez Rezende, Frederic Besse, Fabio Viola,
Ari S. Morcos, Marta Garnelo, Avraham Ruderman, Andrei A. Rusu, Ivo Danihelka,
Karol Gregor, David P. Reichert, Lars Buesing, Theophane Weber, Oriol Vinyals,
Dan Rosenbaum, Neil Rabinowitz, Helen King, Chloe Hillier, Matt Botvinick,
Daan Wierstra, Koray Kavukcuoglu, Demis Hassabis
摘要
场景表征——将视觉感受数据转换成简要描述的过程——是智能行为的一个基础。近来的研究表明,当提供足够大的标签数据时,神经网络在此方面表现优越。然而如何避免对标签的依赖依然是个开放性问题。鉴于此,我们开发了产生式查询网络(Generative Query Network, GQN),在该框架内机器可以只依赖自己的感受器来学习表征。GQN接受从不同视角拍摄的场景图片作为输入,构建内部表征并使用该表征来预测从未观察过的视角的场景图像。GQN做到了不依赖标签或领域知识的表征学习,向机器自动学习理解世界又迈进了一步。
正文
现代人工视觉系统基于深度神经网络,依赖大规模标签数据来学会将图像映射成人为生成的场景描述。很多其他智能任务也是这样做的,比如,对图像中的主要物体进行分类[1],场景类型分类[2],检测物体约束框[3],像素级图像语义标注[4][5]。恰恰相反,现实世界中,神经智能体鲜能获得感受的显式监督数据。高等哺乳动物,像人类婴儿要学会形成表征以便进行运动控制、记忆、规划、想象和快速的技能获取,而不依赖任何社交。而生成式过程被猜测对此能力有所帮助[7-10]。我们渴望创造一个人造系统,可以是学会通过建模数据来表征场景[如二维图像和智能体的空间位置],这些数据是正在处理场景本身的智能体所能直接获得的,而不用依赖语义标签(比如,对象类别、对象位置、场景类别或部分的标签)。
为此,我们提出了生成查询网络GQN,在此框架下,智能体可以在3D场景scene i下游览,它搜集K个2D视角\( v_i^k \)下搜集K张图像\(x_i^k\),并将它们称为一组观察\(o_i=\{(x_i^k, v_i^k)\}_{k=1….K}\)。智能体将这些观察输入GQN,GQN由两部分组成:一个表征网络f,一个生成网络g(图1)。表征网络接收观察,产生一个对场景的表征r,它编码了关于场景的潜在关键信息(为了清晰,我们可以暂且忽略下标i)。每个额外的观察都是对同一表征的更多证据的积累。生成网络则根据任意一个视角查询\(v^q\)来预测场景在该视角的画面,在需要时还会使用随机隐变量z在输出中添加变化元素。这两个网络是以端到端的形式联合训练的,目标是最大化从给定查询视角生成观察到的图像的最大似然估计。更形式化地,(i) \( r=f_\theta(o_i) \),(ii) 深度生成网络定义了使用了隐变量z的场景表征r在视角\(v^q\)观察到的图像x的概率密度分布\( g_\theta(x|v^q,r)=\int g_\theta(x, z|v^q,r)dz \),且(iii) 可学习的参数标记为\(\theta\)。虽然GQN的训练十分困难,由于隐变量z的存在,我们可以借助变分推理,并借助SGD(随机梯度下降)进行优化。
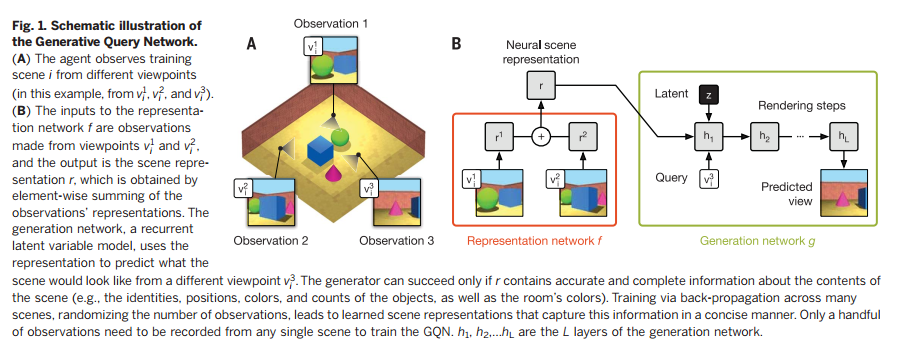
表征网络并不知道生成网络会接到怎样的查询视角请求。因此,它会产生包含全部必要信息(比如物体表示、位置、颜色、计数和空间布局)的表征,这样才能对任意视角查询都能产生最好的图像预测。换句话说,GQN能够自己学会从原始图像中学会这些核心因素。进一步地,生成网络也要内化很多跨场景不变的统计规律(比如,天空的经典颜色,物体的形状规律、对称性、模式和纹理)。这样GQN才能对简明抽象的场景描述保留其表征能力,而生成器负责将细节信息进行填充。比如,无需指定机器臂的具体形状,表征网络只需要关心关节的配置情况,生成网络知晓如何对高级表征使用特定的形状、颜色进行完全填充。相反,体素(voxel, 12-15)或点云(pixel-cloud, 16)方法使用了literal representation,导致在场景复杂度、尺寸变大时表现变差,也不能适应非刚体(动物、植物、服饰)。
多物体空间
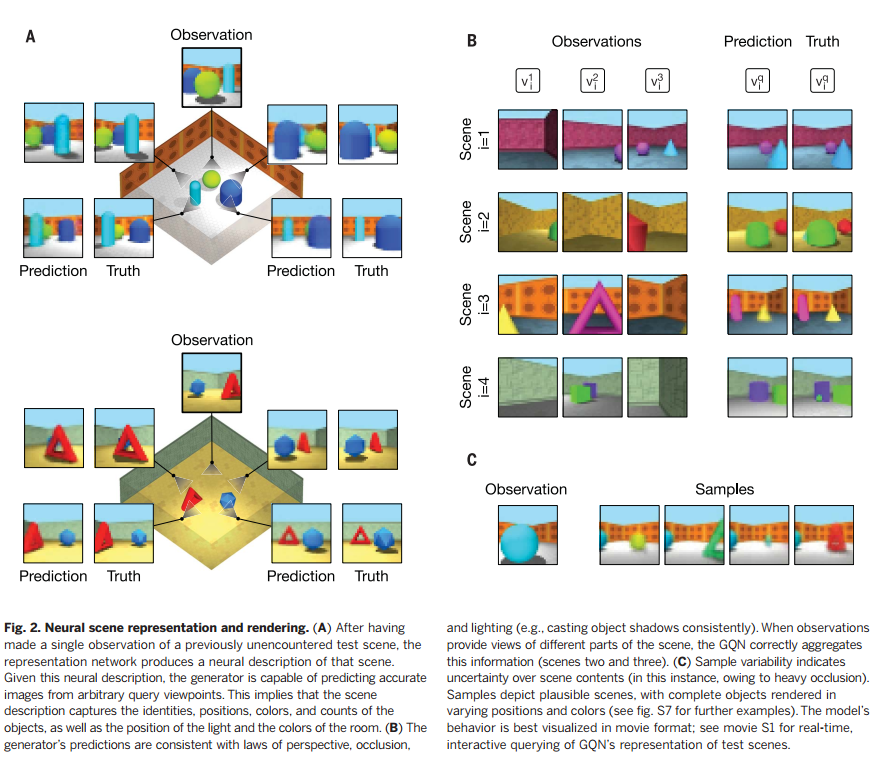
为了验证框架的可行性,我们在一个模拟3D环境中进行实验。第一组实验,我们考虑了一个方形房间放置多种物体。墙的纹理、形状和位置,物体的颜色,光照都是随机的。使得场景可以有无数种可能组合,当然,我们采用的是有限数据集进行的训练和验证[见文献17的第4节有更多细节]。训练后的GQN,给定一个从未见过的测试场景,只要输入一幅或几幅观察图像,就可以计算出它的场景表征。该表征即使只有256维,生成网络对查询视角的预测图像也非常精确很难跟真图区分出来(图2A)。该模型在此类任务可以成功的唯一途径是,在场景表征向量r中,重点关注和有效压缩了每个场景中存在的物体数量、它们在空间中的位置、物体的颜色、墙的颜色以及间接观察到的光源未知。和传统的监督学习方法不同,GQN可以在没有任何人类标注的情况下,对上述情况进行推理。进一步说,GQN生成网络学成了一种类似3D渲染器(一种可以根据场景表征和摄像头视角生成2D图像的程序),而这一切都发生在没有任何先验的关于视角、重叠、光照知识的前提下(图2B)。当通过观察无法显示指定场景内容的时候(比如严重的重叠遮挡),模型就能反映出生成网络的随机采样的不确定性(图2C)。这些特性我们都可以从生成器的实时交互查询视频中看到(视频S1)。
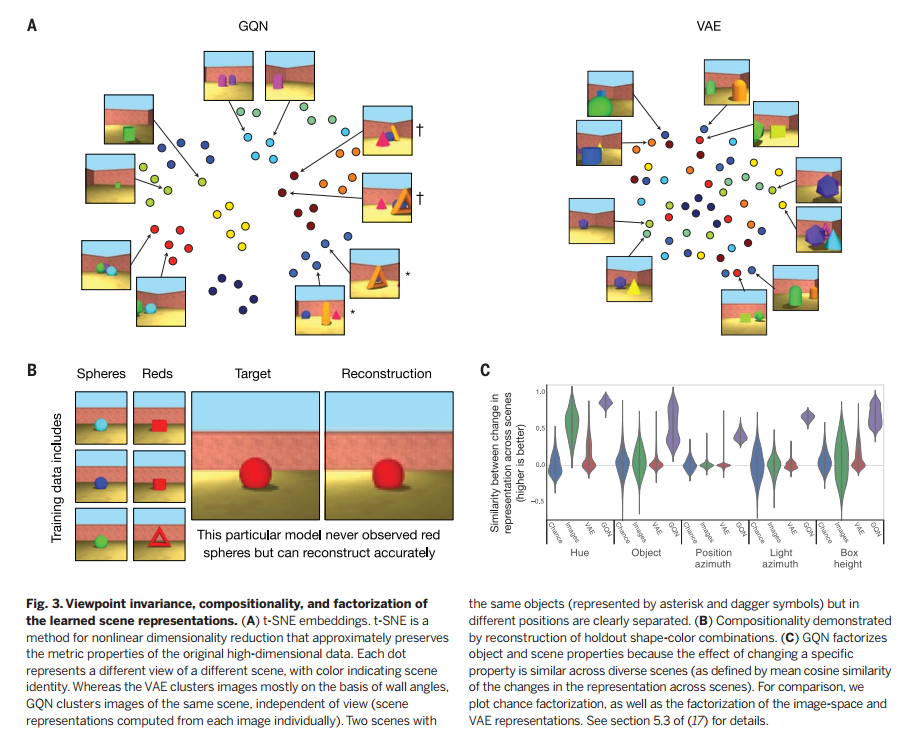
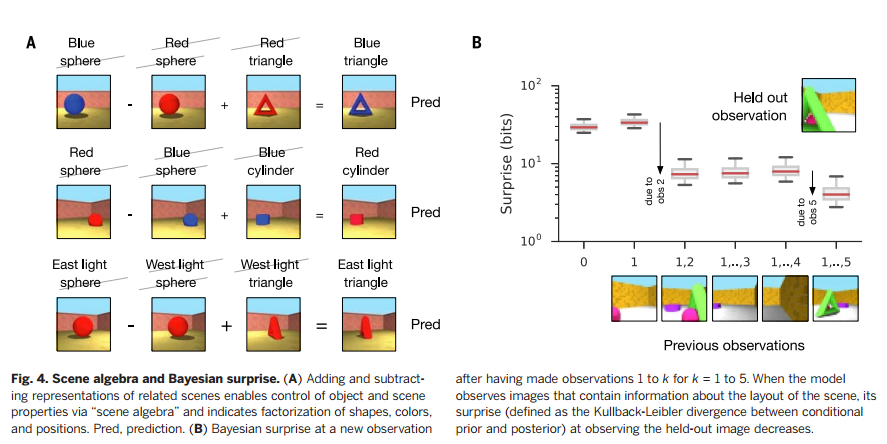
值得注意的是,训练时,每个场景模型只观察很少的图片(实验中,不超过5个),它也能做到较好的预测。我们也监控了训练场景和测试场景的预测观察的似然值(图S3)。总之,这些都说明模型排除了过度拟合的可能性。对训练过的GQN进行分析,我们会发现很多场景表征网络的亮点。GQN场景表征向量的二维T分布随机近邻嵌入(Two-dimensional t-distributed stochastic neighbor embedding, t-SNE[18])可视化过程表明,虽然不同视角有明显的不同,但相同场景下图片仍然有明显聚集性(图3A)。相反,诸如变分自编码器( variational autoencoders, VAE[19])这样的自编码概率密度模型所生成的表征就无法捕获潜在场景的内容(文献17的第5节);它们似乎只是观察图片的表征。而且需要重构一幅目标图像时,GQN会表现出组合行为,因为它能对训练中没有遇见过的场景元素进行表征和渲染,要知道学习这些所有的组合是不可能的。为了验证GQN是否真的学会了核心要素的表征,我们可以研究,如果改变场景的某个属性(比如物体的颜色)其他属性(如尺寸、位置)不变,是否会引起场景表征的类似变化。我们发现物体的颜色、形状、尺寸,光源位置,物体位置都确实被解构出来了(图3C和文献17的5.3、5.4节)。我们还发现GQN可以执行“场景代数”(模仿嵌入代数, embedding algebra这个造词)。通过对相关场景的表征进行加减操作,我们发现物体和场景属性是可以控制的,even across object positions [Fig. 4A and section 5.5 of (17)]。最后,由于GQN是一个概率模型,它也学会了以高效一致的方式从不同视角汇集信息,随着视角数量的增加,每观察到一个场景图片,贝叶斯“惊喜”都会变少(图4B和文献17的第3节)。 我们也分析了GQN扩展到out-of-distribution场景的情况,以及建模Shepard-Metzler物体(见文献17的5.6和4.2)。
机器臂的控制
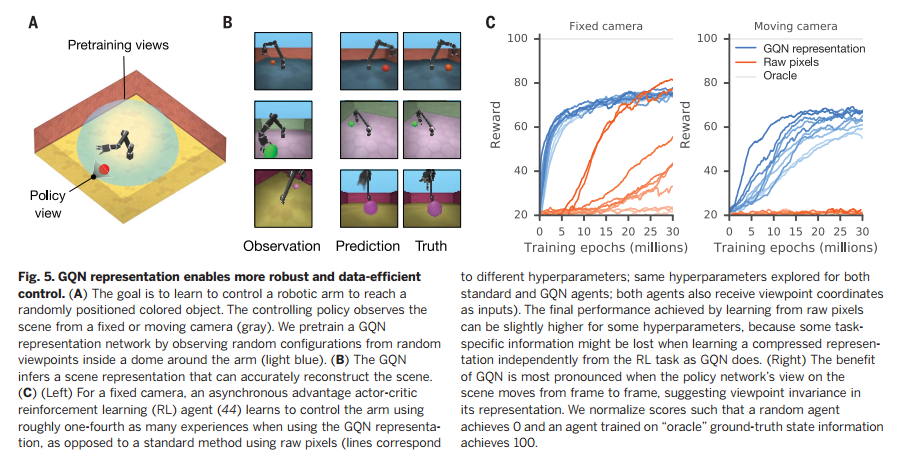
一个表征如果可以简明地反映环境的真实状态,它也能帮助智能体学会在这样的环境中鲁棒地工作,而需要更少的交互。因此,我研究了移动机器臂去触碰有色物体的经典任务,用来测试GQN的表征是否适用于运动控制。深度强化学习的最终目标是从像素中学会控制策略;然而传统方法需要从稀疏的奖励中学习大量的经验。相反,我们先训练GQN,用它来表征观察,然后直接从这些表征中训练策略来控制机器臂。基于这个设计,表征网络必须学会只跟机器臂的关节角度、物体颜色和位置、墙的颜色等进行交流,以便产生去可以预测新的视角。由于该表征比输入的原始图像低太多的维度,我们观察到了十分鲁棒的有效的策略学习,在只进行了使用原始像素的标准方法四分之一的环境交互次数,就达到了收敛时的控制性能(图5和文献17的4.4)。GQN表征的3D本质让我们可以从机械臂周围的任意视角训练策略,并且足够稳定地在一个自由移动的摄像机下进行机械臂速度控制。
部分观察视角的迷宫环境
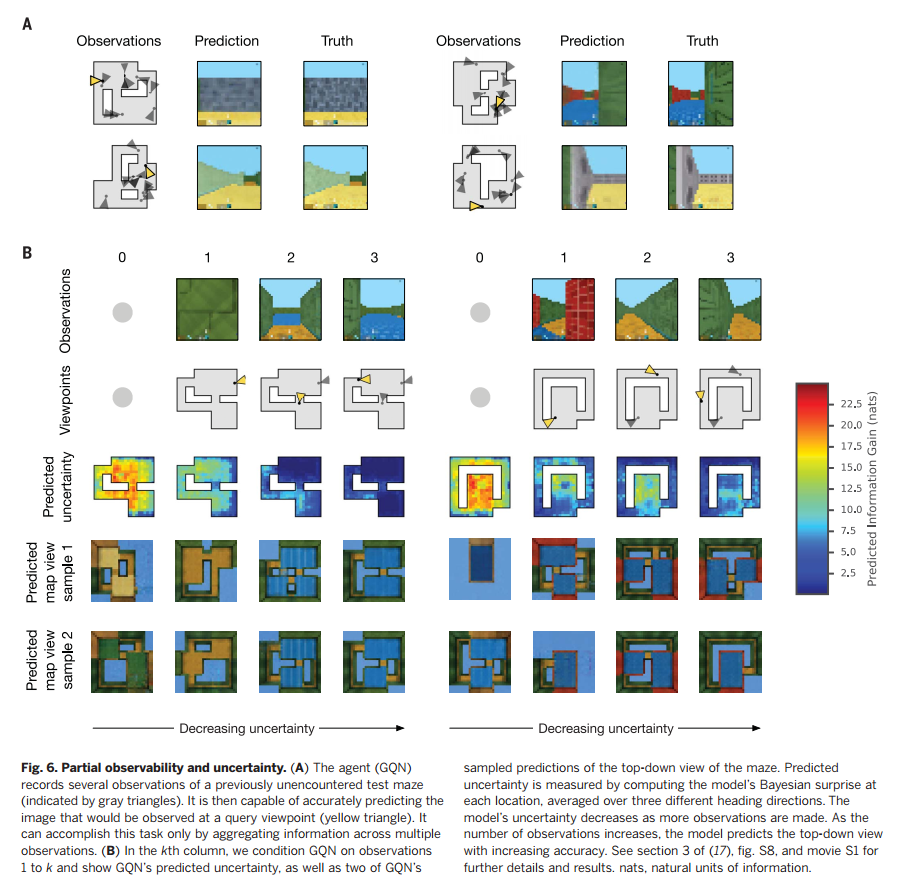
最后,我们考虑了更加复杂、程序式的类迷宫环境,以测试GQN的扩展能力。迷宫由多个房间组成,通过走廊进行连接,每个场景中,每个迷宫的布局、墙体的颜色都是随机的。在这个实验设计中,任何单一的观察都只能提供整个迷宫信息的一小部分。像之前一样,GQN的训练目标是可以从一个全新的视角预测迷宫图像,只有GQN可以成功聚集不同视角的多个观察进而确定迷宫的布局,预测才有可能实现。我们发现GQN能够以新的第一人称视角进行正确的预测(图6A)。我们对GQN的表征进行了更为直接的查撇,即训练一个独立的生成器网络来预测迷宫的自顶向下视角,发现它可以产生高度准确的预测(图6B)。模型的不确定性,即它第一人称视角样本的熵,会随着观察的增多而降低(图6B,文献17的第3节)。大约5次观察之后,GQN的不确定性基本就完全消失了。
相关工作
【翻译略】
展望
【翻译略】
参考文献
1. A. Krizhevsky, I. Sutskever, G. E. Hinton, in Advances in Neural
Information Processing Systems 25 (NIPS 2012), F. Pereira,
C. J. C. Burges, L. Bottou, K. Q. Weinberger, Eds. (Curran
Associates, 2012), pp. 1097–1105.
2. B. Zhou, A. Lapedriza, J. Xiao, A. Torralba, A. Oliva, in Advances
in Neural Information Processing Systems 27 (NIPS 2014),
Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence,
K. Q. Weinberger, Eds. (Curran Associates, 2014), pp. 487–495.
3. S. Ren, K. He, R. Girshick, J. Sun, in Advances in Neural
Information Processing Systems 28 (NIPS 2015), C. Cortes,
N. D. Lawrence, D. D. Lee, M. Sugiyama, R. Garnett, Eds.
(Curran Associates, 2015), pp. 91–99.
4. R. Girshick, J. Donahue, T. Darrell, J. Malik, in Proceedings of
the 2014 IEEE Conference on Computer Vision and Pattern
Recognition (CVPR) (IEEE, 2014), pp. 580–587.
5. M. C. Mozer, R. S. Zemel, M. Behrmann, in Advances in Neural
Information Processing Systems 4 (NIPS 1991), J. E. Moody,
S. J. Hanson, R. P. Lippmann, Eds. (Morgan-Kaufmann, 1992),
pp. 436–443.
6. J. Konorski, Science 160, 652–653 (1968).
7. D. Marr, Vision: A Computational Investigation into the Human
Representation and Processing of Visual Information
(Henry Holt and Co., 1982).
8. D. Hassabis, E. A. Maguire, Trends Cogn. Sci. 11, 299–306
(2007).
9. D. Kumaran, D. Hassabis, J. L. McClelland, Trends Cogn. Sci.
20, 512–534 (2016).
10. B. M. Lake, R. Salakhutdinov, J. B. Tenenbaum, Science 350,
1332–1338 (2015).
11. S. Becker, G. E. Hinton, Nature 355, 161–163 (1992).
12. Z. Wu et al., in Proceedings of the 2015 IEEE Conference on
Computer Vision and Pattern Recognition (CVPR) (IEEE, 2015),
pp. 1912–1920.
13. J. Wu, C. Zhang, T. Xue, W. Freeman, J. Tenenbaum, in Advances
in Neural Information Processing Systems 29 (NIPS 2016),
D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, R. Garnett,
Eds. (Curran Associates, 2016), pp. 82–90.
14. D. J. Rezende et al., in Advances in Neural Information
Processing Systems 29 (NIPS 2016), D. D. Lee, M. Sugiyama,
U. V. Luxburg, I. Guyon, R. Garnett, Eds. (Curran Associates,
2016), pp. 4996–5004.
15. X. Yan, J. Yang, E. Yumer, Y. Guo, H. Lee, in Advances in Neural
Information Processing Systems 29 (NIPS 2016), D. D. Lee,
M. Sugiyama, U. V. Luxburg, I. Guyon, R. Garnett, Eds. (Curran
Associates, 2016), pp. 1696–1704.
16. M. Pollefeys et al., Int. J. Comput. Vision 59, 207–232 (2004).
17. See supplementary materials.
18. L. van der Maaten, J. Mach. Learn. Res. 9, 2579–2605 (2008).
19. I. Higgins et al., at International Conference on Learning
Representations (ICLR) (2017).
20. T. Mikolov et al., in Advances in Neural Information Processing
Systems 26 (NIPS 2013), C. J. C. Burges, L. Bottou, M. Welling,
Z. Ghahramani, K. Q. Weinberger, Eds. (Curran Associates, 2013),
pp. 3111–3119.
21. Y. Zhang, W. Xu, Y. Tong, K. Zhou, ACM Trans. Graph. 34, 159
(2015).
22. D. P. Kingma, M. Welling, arXiv:1312.6114 [stat.ML]
(20 December 2013).
23. D. J. Rezende, S. Mohamed, D. Wierstra, in Proceedings of the
31st International Conference on Machine Learning (ICML 2014)
(JMLR, 2014), vol. 32, pp. 1278–1286.
24. I. Goodfellow et al., in Advances in Neural Information Processing
Systems 27 (NIPS 2014), Z. Ghahramani, M. Welling, C. Cortes,
N. D. Lawrence, K. Q. Weinberger, Eds. (Curran Associates, 2014),
pp. 2672–2680.
25. K. Gregor, F. Besse, D. J. Rezende, I. Danihelka, D. Wierstra,
in Advances in Neural Information Processing Systems 29 (NIPS
2016), D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon,
R. Garnett, Eds. (Curran Associates, 2016), pp. 3549–3557
26. P. Vincent, H. Larochelle, Y. Bengio, P.-A. Manzagol, in
Proceedings of the 25th International Conference on Machine
Learning (ICML 2008) (ACM, 2008), pp. 1096–1103.
27. P. Dayan, G. E. Hinton, R. M. Neal, R. S. Zemel, Neural Comput.
7, 889–904 (1995).
28. G. E. Hinton, A. Krizhevsky, S. D. Wang, in Proceedings of the
21st International Conference on Artificial Neural Networks
and Machine Learning (ICANN 2011), T. Honkela, W. Duch,
M. Girolami, S. Kaski, Eds. (Lecture Notes in Computer Science
Series, Springer, 2011), vol. 6791, pp. 44–51.
29. C. B. Choy, D. Xu, J. Gwak, K. Chen, S. Savarese, in
Proceedings of the 2016 European Conference on Computer
Vision (ECCV) (Lecture Notes in Computer Science Series,
Springer, 2016), vol. 1, pp. 628–644.
30. M. Tatarchenko, A. Dosovitskiy, T. Brox, in Proceedings of the
2016 European Conference on Computer Vision (ECCV)
(Lecture Notes in Computer Science Series, Springer, 2016),
vol. 9911, pp. 322–337.
31. F. Anselmi et al., Theor. Comput. Sci. 633, 112–121 (2016).
32. D. F. Fouhey, A. Gupta, A. Zisserman, in Proceedings of the 2016
IEEE Conference on Computer Vision and Pattern Recognition
(CVPR) (IEEE, 2016), pp. 1516–1524.
33. A. Dosovitskiy, J. T. Springenberg, M. Tatarchenko, T. Brox,
IEEE Trans. Pattern Anal. Mach. Intell. 39, 692–705 (2017).
34. C. Godard, O. Mac Aodha, G. J. Brostow, in Proceedings of
the 2017 IEEE Conference on Computer Vision and Pattern
Recognition (CVPR) (IEEE, 2017), pp. 6602–6611.
35. T. Zhou, S. Tulsiani, W. Sun, J. Malik, A. A. Efros, in
Proceedings of the 2016 European Conference on Computer
Vision (ECCV) (Lecture Notes in Computer Science Series,
Springer, 2016), pp. 286–301.
36. J. Flynn, I. Neulander, J. Philbin, N. Snavely, in Proceedings of
the 2016 IEEE Conference on Computer Vision and Pattern
Recognition (CVPR) (IEEE, 2016), pp. 5515–5524.
37. T. Karras, T. Aila, S. Laine, J. Lehtinen, arXiv:1710.10196 [cs.NE]
(27 October 2017).
38. A. van den Oord et al., in Advances in Neural Information
Processing Systems 29 (NIPS 2016), D. D. Lee, M. Sugiyama,
U. V. Luxburg, I. Guyon, R. Garnett, Eds. (Curran Associates,
2016), pp. 4790–4798.
39. D. Jayaraman, K. Grauman, in Proceedings of the 2015 IEEE
International Conference on Computer Vision (ICCV) (IEEE,
2015), pp. 1413–1421.
40. P. Agrawal, J. Carreira, J. Malik, arXiv:1505.01596 [cs.CV]
(7 May 2015).
41. A. R. Zamir et al., in Proceedings of the 2016 European
Conference on Computer Vision (ECCV) (Lecture Notes in
Computer Science Series, Springer, 2016), pp. 535–553.
42. T. D. Kulkarni, P. Kohli, J. B. Tenenbaum, V. Mansinghka,
in Proceedings of the 2015 IEEE Conference on Computer
Vision and Pattern Recognition (CVPR) (IEEE, 2015),
pp. 4390–4399.
43. Q. Chen, V. Koltun, in Proceedings of the 2017 IEEE
International Conference on Computer Vision (ICCV) (IEEE,
2017), pp. 1511–1520.
44. A. A. Rusu et al., arXiv:1610.04286 [cs.RO] (13 October 2016).