本文实现了Fast-RCNN主要部分的翻译工作,在SPPnet出来之后,同在微软的R-CNN的作者Ross迅速怼了回去,抛出了更快更好的Fast-RCNN,思路为之一新的是,将之前的多阶段训练合并成了单阶段训练,这次的工作简洁漂亮,相比之前的RCNN,怀疑作者是在挤牙膏。另外,面对灵活尺寸问题,Ross借鉴了空间金字塔的思路,使用了一层空间金字塔。
Fast R-CNN
Ross Girshick
Microsoft Research
rbg@microsoft.com
摘要
本文提出了一个快速的基于区域推荐的卷积网络方法(Fast R-CNN)用于对象检测。Fast R-CNN在前人工作的基础上使用深度卷积网络,可以更有效地分类物体推荐。相比之前的工作,Fast R-CNN进行了多项创新,在提高了检测精度的同时,也提高了训练和测试速度。Fast R-CNN训练了一个超深VGG16网络,训练时间比R-CNN快9倍,测试时间快213倍,在PASCAL VOC2012上达到了更高的mAP。相比SPPnet,Fast R-CNN训练快3倍,测试快10倍,并且更加准确。Fast R-CNN用Python和C++(使用Caffe)实现,以MIT协议开放在:https://github.com/rbgirshick/fast-rcnn
1. 介绍
近来,深度卷积网络[14][16]在图像分类[14]和物体检测[9][19]精度上进展显著。相比物体分类,物体定位更具挑战,需要更加复杂的方法。由于其复杂性,当前的方法[9][11][19][25]都是多阶段流水线模型训练,缓慢而粗放。
复杂度源于检测需要物体的精准位置信息,带来了两个基本挑战。一、大量候选位置需要处理(通常称为“推荐”proposals)。二、这些候选框的位置比较粗糙,必须进一步细化才能精准定位。对这些问题的解决包括速度、精度或简易性。
本文将梳理现代卷积网络物体检测器的训练流程[9][11]。提出一个单阶段训练算法,既能学习对推荐框进行分类,也能精细空间位置。
最终得到的方法可以训练一个深度检测网络(VGG16[20]),比R-CNN[9]快9倍,比SPPnet[11]快3倍。运行时,该检测网络每0.3s处理一张图片(不包括物体推荐时间),而且在PASCAL VOC2012[7]上的准确度达到新的高度,mAP66%(而R-CNN为62%)。
1.1 R-CNN和SPPnet
基于区域的深度卷积网络RCNN[9]通过使用深度卷积网络分类物体推荐达到了出色的物体检测成绩。但其缺点十分明显:
1. 需要多阶段流水线训练。R-CNN需要先使用log loss在物体推荐上调优卷积网络,然后,还要让SVMs去适应卷机网络的特征。这些SVMs取代了通过调优学到的softmax分类器,成为物体检测器。在第三阶段,还要进行约束框回归。
2. 训练费时费空间。对于SVM和约束框回归的训练,特征是从每张图片的每个物体推荐中抽取出来再写到硬盘的。对于非常深的网络,比如VGG16,对VOC07训练验证集这个过程需要消耗2.5GPU天。这些特征需要数百G的存储空间。
3. 物体检测非常慢。测试阶段,每张测试图像的每个物体推荐都要进行特征抽取。VGG16检测每张图像需要在GPU上耗费47s。
R-CNN如此之慢,就是因为在每个推荐上都是用卷积网络,没有共享计算。空间金字塔池化网络(SPPnets)[11]则通过共享计算加速了R-CNN。SPPnet方法对整张输入图像只计算一次卷积特征图,然后对每个对象推荐使用从共享特征图中抽取出来的特征向量进行分类。对于每一个推荐,通过最大池化推荐框内的部分特征图到一个固定尺寸(比如6×6)的输出来抽取特征。多个输出尺寸被池化,然后在使用空间金字塔池化进行连接。SPPnet在测试阶段加速了R-CNN大概10到100倍。训练时间也缩减了3倍,因为特征的抽取快了很多。
SPPnet也有明显的缺点。像R-CNN一样,它也训练一个多阶段流水线涉及到特征抽取、使用log loss调优网络,训练SVMs,最后再进行约束框回归。特征还要写到硬盘。但不同于R-CNN的是,[11]中的调优算法没法更新空间金字塔池化层前面的卷积层。不出所料,这个限制(固定的卷积层)限制了非常深的网络的精度。
1.2 贡献
我们提出一个全新的训练算法,可以解决R-CNN和SPPnet的这些缺点,还能提高速度和精度。因为其在训练和测试阶段都明显地快,所以我们称之为Fast R-CNN。Fast R-CNN方法有多个有点:
1. 更高的检测质量(mAP)
2. 使用多任务loss进行单阶段训练
3. 训练可以更新所有层
4. 不需要硬盘存储特征缓存
Fast R-CNN用Python和C++(Caffe[13])写成,以开源MIT协议开放在 https://github.com/rbgirshick/fast-rcnn。
2. Fast R-CNN架构和训练
图1展示了Fast R-CNN的架构。一个Fast R-CNN网络将整张图片和一组对象推荐作为输入。网络首先使用卷积网络和最大池化处理整张图像产生卷积特征图。然后对每个对象推荐,一个兴趣区域(Region of Interest, RoI)池化层从特征图中抽取出一个固定尺寸的特征向量。每个特征向量喂给后续一系列的全连接层(fc),这些全连接层,最终分裂成两个并行的输出层,一个用于产生K+1(1代表背景)类的softmax概率,一个针对每个对象类别输出四个实数值。每组实数值编码了对应类别约束框的位置。

2.1 RoI池化层
RoI池化层使用最大池化将任何有效区域内的特征转化成一个小的带有固定空间范围HxW(比如7×7)的特征图,其中H和W是层的超参数,和任何特定的RoI无关。本文中,一个RoI是针对卷积特征图的一个矩形窗口。每个RoI定义成四元组(r, c, h, w),左上角为(r, c),高和宽是(h, w)。
RoI最大池化将hxw的RoI窗口分成HxW的子窗口网格,每个子窗口大小大约是h/H x w/W。然后每个子窗口进行最大池化放入网格对应的单元。池化以标准最大池化的形式独立应用在每个特征图的channel上。RoI层是SPPnets中的空间金字塔层的一个特例[11],因为他是一个一层的金字塔结构。我们使用[11]中的子窗口池化方法。
2.2 从预训练网络中初始化
我们实验了三个预训练ImageNet[4]网络,每个都有5个最大池化层,5-13个卷积层(见4.1节)。当用一个预训练的网络初始化一个Fast R-CNN网络需要经历三个转换。
一、最后的最大池化层要替换成RoI池化层,配置的参数H和W要与网络的第一个全连接层想适应(对于VGG16来说,就是H=W=7)。
二、网络的最后一个卷积层和softmax(1000路ImageNet分类)层要替换成两个并行的层。一个是全连接层并输出K+1路的softmax,一个是类别相关的约束框回归器。
三、网络修改为接受两个数据输入:一组图像和一组这些图像的RoI。
2.3 检测调优
使用反向传播训练所有的网络参数是Fast R-CNN的重要能力。首先,需要阐明为什么SPPnet不能更新金字塔层前面的卷积层权重。根本的原因是当第一个训练样本(也就是RoI)来自于另一张图片时,反向传播通过SPP层时十分低效,而R-CNN和SPPnet需要这样训练。这是每个RoI都有很大的感受野,经常跨整张图片。既然前向传播过程必须处理整个感受野,训练输入又非常的大(通常是整张图像)。
我们提出一个更加高效的训练方法,可以在训练过程中发挥特征共享的优势。在Fast R-CNN训练过程中随机梯度下降SGD的mini batch是分层采样的,首先采样N张图像,然后从每张图片采样R/N个RoI。来自同一张图片的RoI在前向和后向传播中共享计算和内存。这样就可以减少mini-batch的计算量。例如N=2,R=128,这个训练模式大概比从128个不同的图像采样1个RoI(这就是R-CNN和SPPnet的训练方式)要快64倍。
该策略一个问题是会导致收敛起来比较慢,因为来自同一张图片的RoI是相关的。但它在实际中并没有成为一个问题,我们的使用N=2和R=128达到了很好的成绩,只用了比R-CNN还少的SGD迭代。
除了分层采样外,Fast R-CNN使用了一个改进的训练过程,只用一个调优的阶段就可以联合优化softmax分类器和约束框回归器,而不是训练分三个阶段分别训练一个softmax分类器、一堆SVMs和回归器[9][11]。这个过程的要件(loss, mini-batch采样策略,RoI池化层反向传播方法,SGD的超参数)描述如下。
Multi-task Loss。Fast R-CNN有两个输出层。第一个是针对每个RoI的离散概率分布,p = (p_0, …, p_k),k+1为类别总数。通常,p的计算是在全连接层的K+1个输出上应用softmax。第二个层的输出是约束框回归的偏移量,对于第k类而言,t^k = (t^k_x, t^k_y, t^k_w, t^k_h)。我们使用[9]中的t^k参数化方法,t^k指定了相对一个对象推荐的缩放无关的平移和log空间内的宽高变化。
每个RoI都使用真实类属u和真实的约束框回归目标v进行标注。我们对每个RoI使用多任务Loss L用来进行分类和约束框回归的联合训练:

其中L_{cls}(p, u) = -logp_u是真实类属u的log loss。
第二个loss L_{loc}是定义两个元组上,第一个元组是针对类u的真实标注约束框回归目标 v=(v_x, v_y, v_w, v_h),第二个也是针对类u的预测元组t^u = (t^u_x, t^u_y, t^u_w, t^u_h)。中括号项代表这样一个函数:当u ≥ 1时,返回1,否则返回0。根据约定代表全部剩余一切的背景类标注成u=0。所以对于背景RoI而言,没有真是标注框信息,因而L_{loc}就忽略了。对于约束框回归,我们使用这个Loss:
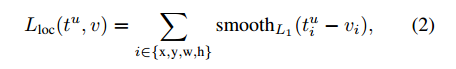

其中,
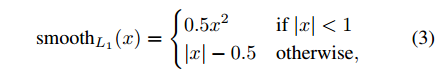
它是L1Loss,比较鲁棒,没有R-CNN和SPPnet中使用的L2 Loss对异常值那么敏感。当回归目标不受控时,使用L2 Loss训练需要更加细心的learning rate调整以避免梯度爆炸。等式3消除了这个敏感性。
等式1中的超参数λ用于调整两个loss的平衡。我们归一化回归目标v_i到期望0和单位方差。所有的实验都是用λ = 1。
我们注意到[6]是用了一个相关的loss用于训练未知类物体推荐网络。不同于我们方法的是,[6]主张是用两个网络以分开定位和分类。Overfeat[19],R-CNN[9]和SPPnet[11]也分开训练分类器和约束框定位器,但这些方法都得分阶段进行训练,对来Fast R-CNN不是最佳选择(5.1节)。
Mini-batch采样。调优过程中,每个SGD mini-batch是从N=2张图片中构建的,图片的选择是均匀随机选择(实践中我们直接对数据集的排列组合进行迭代)。我们使用的mini-batch大小是R=128,每张图片采样64个预取。在[9]中,我们从物体推荐的RoI中选取25%,这些推荐都是和真实标注框有至少0.5的重合度。参照[11],这些RoIs包括标注为前景类别的样例,也就是u ≥ 1。其他的样例从重叠度为[0.1, 0.5)的推荐中采样,也就是u=0的背景样例。低于0.1的阈值似乎可以作为难样例挖掘算法[8]的启发值。训练过程中,图像由0.5的概率被水平翻转。没有其他的数据增强了。
RoI池化层的反向传播。反向传播需要求解RoI池化层的偏导。为了更加清晰易懂,我们假设mini-batch只有一个图像(N=1),N>1的情况也很简单,因为每个图像都是单独传递的。
令x_i \belongs \Real 代表RoI池化层的第i个激活输入。令y_{rj}代表从第r个RoI到该层的第j个输出。RoI池化层就是计算$y_{rj} = x_{i*(r, j)}$,其中$i*(r, j) = argmax_{x_i’\belongs R(r, j)}x_i’$。$R(r, j)$是子窗口中输入的索引集合,$y_{rj}$在这个子窗口上进行最大池化。单一的x_i也许会赋值给不同的输出$y_{rj}$。
RoI池化层的反向传播函数计算loss函数对每个输入x_i的偏导数:
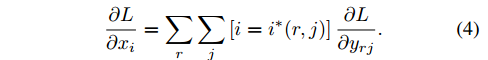
换句话说,对于每个mini-batch RoI r和对于每个池化输出单元y_{rj},如果i被最大池化选中,偏导数$\partial L / \partial y_{rj}$就会累加。反向传播过程中,偏导数$\partial L / \partial y_{rj}$在RoI池化层的上一层计算完成。
SGD超参数。【略】
2.4 缩放不变性
我们研究了两种达到缩放变性物体检测的方法:(1)通过“暴力”学习和(2)使用图像金字塔。这些策略遵照[11]。暴力法中,每个图像被处理成各种预设尺寸。网络从训练数据中直接学习缩放不变性的物体检测。
相反,多尺度方法中,通过图像金字塔向网络提供缩放不变性的近似。在测试阶段,图像金字塔被用于对每个物体推荐进行近似缩放归一化。遵照[11],在多尺度训练时,每次选择一个图像,我们随机采样一个金字塔尺度,算作一种图像增强手段。限于GPU限制,我们的多尺度训练实验只能在较小的网络上进行。
3. Fast R-CNN检测
一旦一个Fast R-CNN调优好,检测就是运行一次前向传播(假设物体推荐已经事先计算好了)。网络对输入的图像(或者一个图像金字塔,编码成一系列图像)和R个对象推荐的列表进行打分。尽管我们一直分析更大的类别数量(≈ 45k),但测试阶段R一般都是2000左右。使用图像金字塔是,每个RoI都赋值给一个能让RoI接近2242像素的尺度[11]。
对于每个测试RoI r,前向传播输出类的后验概率分布p和一个预测的约束框相对r的偏移值(对于每个类别K都有一个偏移量预测)。我们针对每个类别k对r赋予一个检测置信值,预估概率$Pr(class=k|r) \triaglequal p_k$,然后使用对每个类别分别应用R-CNN[9]中使用的非最大值抑制算法
3.1 用于更快检测的截断SVD
对于全图像分类,全连接层的时间消耗跟卷积层相比还是很小的。形成对比的是,对于检测,RoIs的数量很大,导致全连接层的计算量几乎占用了前向传播的一般时间(见图2)。大型全连接层可以通过使用截断SVD[5][23]压缩并非常方便地加速。
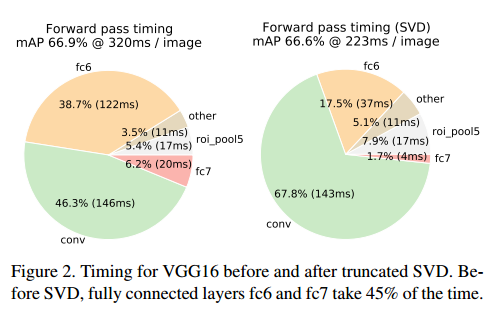
【略】
4. 主要结果
三个主要结果支撑了本文的贡献:
1. VOC07,2010和2012上最高水平的mAP
2. 相比R-CNN,SPPnet更加快读的训练和测试时间
3. VGG16上调优的卷基层提高了mAP
4.1. 实验环境
我们的实验使用三个预训练好的ImageNet模型,都可以在网上获取到。第一个是来自R-CNN的CaffeNet(本质是一个AlexNet[14])。我们用S指代这个模型,表示“small”。第二个网络是VGG_CNN_M_1024[3],和S有同样的深度,但更宽,称为M,代表“Medium”。最后一个是非常深的VGG16模型[20]。既然这个模型是最大的,我们称为L。本节中所有的实验都是单一尺度训练和测试(s=600;5.2节有详细介绍)。
4.2 VOC 2010 and 2012 results
【略】
4.3. VOC 2007 results
【略】
4.4. Training and testing time
【略】
4.5. Which layers to fine-tune?
【略】
5. 设计评价分析
我们设计了一些实验来理解Fast R-CNN,并评价这些设计决定。按照最佳实践,这些实验在VOC07数据集上进行。
【略】
6. 结论
本文提示了Fast R-CNN,一个清晰快读的R-CNN和SPPnet的升级版。除了报告了牛逼的检测结果,我们还做了一些实验希望提供更多的见解。尤其注意的是稀少的对象推荐似乎能提高检测器的质量。过去研究这个问题在时间上过于昂贵,但Fast R-CNN上变得可行。当然,也许会有未发现的密集框技术可以和稀疏推荐效果一样好。如果这种方法被开发出来,也许会进一步提升对象检测的表现。
References
[1] J. Carreira, R. Caseiro, J. Batista, and C. Sminchisescu. Semantic segmentation with second-order pooling. In ECCV,2012.
[2] R. Caruana. Multitask learning. Machine learning, 28(1),1997.
[3] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman.Return of the devil in the details: Delving deep into convolutional nets. In BMVC, 2014.
[4] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. FeiFei. ImageNet: A large-scale hierarchical image database.In CVPR, 2009.
[5] E. Denton, W. Zaremba, J. Bruna, Y. LeCun, and R. Fergus.Exploiting linear structure within convolutional networks forefficient evaluation. In NIPS, 2014.
[6] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalableobject detection using deep neural networks. In CVPR, 2014.3
[7] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, andA. Zisserman. The PASCAL Visual Object Classes (VOC)Challenge. IJCV, 2010.
[8] P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained partbased models. TPAMI, 2010.
[9] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semanticsegmentation. In CVPR, 2014.
[10] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Regionbased convolutional networks for accurate object detectionand segmentation. TPAMI, 2015.
[11] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid poolingin deep convolutional networks for visual recognition. InECCV, 2014.
[12] J. H. Hosang, R. Benenson, P. Dollar, and B. Schiele. What ´makes for effective detection proposals? arXiv preprintarXiv:1502.05082, 2015.
[13] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutionalarchitecture for fast feature embedding. In Proc. of the ACMInternational Conf. on Multimedia, 2014.
[14] A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS,2012.
[15] S. Lazebnik, C. Schmid, and J. Ponce. Beyond bags offeatures: Spatial pyramid matching for recognizing naturalscene categories. In CVPR, 2006.
[16] Y. LeCun, B. Boser, J. Denker, D. Henderson, R. Howard,W. Hubbard, and L. Jackel. Backpropagation applied tohandwritten zip code recognition. Neural Comp., 1989.
[17] M. Lin, Q. Chen, and S. Yan. Network in network. In ICLR,2014.
[18] T. Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick,J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zit- ´nick. Microsoft COCO: common objects in context. arXive-prints, arXiv:1405.0312 [cs.CV], 2014.
[19] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus,and Y. LeCun. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. In ICLR,2014.
[20] K. Simonyan and A. Zisserman. Very deep convolutionalnetworks for large-scale image recognition. In ICLR, 2015.
[21] J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders.Selective search for object recognition. IJCV, 2013.
[22] P. Viola and M. Jones. Rapid object detection using a boostedcascade of simple features. In CVPR, 2001.
[23] J. Xue, J. Li, and Y. Gong. Restructuring of deep neuralnetwork acoustic models with singular value decomposition.In Interspeech, 2013.
[24] X. Zhu, C. Vondrick, D. Ramanan, and C. Fowlkes. Do weneed more training data or better models for object detection? In BMVC, 2012.
[25] Y. Zhu, R. Urtasun, R. Salakhutdinov, and S. Fidler.segDeepM: Exploiting segmentation and context in deepneural networks for object detection. In CVPR, 2015.