这个是幂次学院的机器学习课程大纲,非常适合自学者给自己做参考用。注意这个不是深度学习为主的课程,机器学习的传统理论就满满一大筐了。
第一部分 基础篇
第1章 初识机器学习
1.1 引言
1.2 基本术语
1.3 假设空间
1.4 归纳偏好
1.5 发展历程
1.6 应用现状
这个是幂次学院的机器学习课程大纲,非常适合自学者给自己做参考用。注意这个不是深度学习为主的课程,机器学习的传统理论就满满一大筐了。
第一部分 基础篇
第1章 初识机器学习
1.1 引言
1.2 基本术语
1.3 假设空间
1.4 归纳偏好
1.5 发展历程
1.6 应用现状
By Dr Emmi Pikler
An excerpt PEACEFUL BABIES – CONTENTED MOTHERS (published in 1940),
taken from the Sensory Awareness Foundation publication BULLETIN (Number 14/Winter 1994).
Children, particularly in cities, tend to sit poorly and have bad posture. They cannot sit, stand or walk properly, not to mention more complicated movements.
This, of course, is not self-evident to every reader. I can hear the astonished responses: “What? My children can’t move?!” “My little daughter could already sit when she was just four months old” “Mine was already standing at six months”… “When my son was not even one year old, he was walking.”
Read more
本文对论文《world Models》的前半部分进行了翻译,看过前半部分基本就了解结构了,我个人认为Schmidhuber还是一如既往地喜欢把小东西往宏大了说,当然也多亏了他起的题目,很多人对世界模型产生了浓厚的兴趣。但本文的确不能说在世界模型方面有了飞跃的进步,只是将隐变量配合LSTM当作了世界模型,所以我不打算翻译后半部分了。虽然现在大家对于时序问题还没有太好的办法,很多时候不得不靠LSTM,但LSTM绝对不是未来。
我们研究在流行的强化学习环境中构建生成神经网络。以监督的方式可以快速训练我们的世界模型学会环境的压缩空间和时间表征。将从世界模型中抽取的特征作为智能体的输入,我们能训练出一个非常紧凑简单的指定任务解决策略。我们也能训练智能体完全沉浸在自己的幻觉中基于它的世界模型做梦,并将策略迁移回实际环境中。
本文对Deepmind最新成果GQN论文的主要部分进行了翻译
S. M. Ali Eslami, Danilo Jimenez Rezende, Frederic Besse, Fabio Viola,
Ari S. Morcos, Marta Garnelo, Avraham Ruderman, Andrei A. Rusu, Ivo Danihelka,
Karol Gregor, David P. Reichert, Lars Buesing, Theophane Weber, Oriol Vinyals,
Dan Rosenbaum, Neil Rabinowitz, Helen King, Chloe Hillier, Matt Botvinick,
Daan Wierstra, Koray Kavukcuoglu, Demis Hassabis
场景表征——将视觉感受数据转换成简要描述的过程——是智能行为的一个基础。近来的研究表明,当提供足够大的标签数据时,神经网络在此方面表现优越。然而如何避免对标签的依赖依然是个开放性问题。鉴于此,我们开发了产生式查询网络(Generative Query Network, GQN),在该框架内机器可以只依赖自己的感受器来学习表征。GQN接受从不同视角拍摄的场景图片作为输入,构建内部表征并使用该表征来预测从未观察过的视角的场景图像。GQN做到了不依赖标签或领域知识的表征学习,向机器自动学习理解世界又迈进了一步。
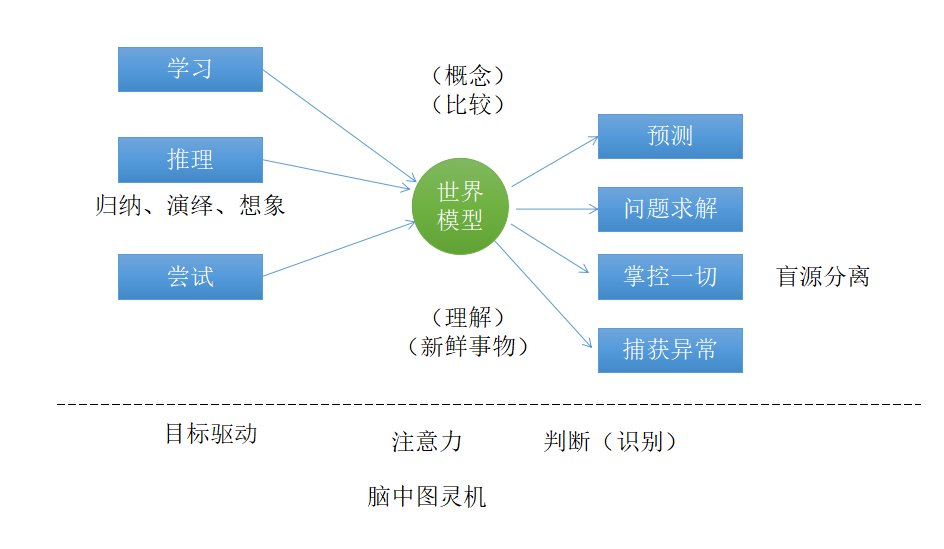
本文粗浅地讨论我对一些重要概念的理解:记忆 理解 概念 特征世界 识别 比较 归纳 预测 激励 推理 视觉推理 陌生事物 新鲜感 发现异常 生成网络 尝试 想象 动机 目标驱动 脑中图灵机 盲源分离 目标达成 世界模型 回忆 注意力 感知 判断 感觉世界feeling
记忆(Memory)——有很多子类型,比如短时记忆、长时记忆,情景记忆、陈述性记忆、程序性记忆等等,不一而足,记忆直接对应着连接关系与其权重,将0也看成权重的话,本质是权重对外界影响的落实。比如一个场景,连续的感觉输入包括相关概念的唤醒,也包括时间性感觉和概念,时间性的记忆由前后关系型连接建立,发生的事物、以及事物的空间和时间关系都影响着大量连接的权重,尤其是一过性场景能形成长期记忆,可能以来脑中的回放机制来加强记忆。短时记忆机制的已逝性和与长时记忆的可塑性,说明权重变化既是敏感的也是可加强的,有可能不同特性的连接用于不同的功能,有些连接比较迟钝,权重落实慢,需要反复刺激,有些权重落实快,增加快降低也快,可塑性太强,反复变化,不便于长期记忆。说到记忆,往往指的是我们意识能感知到的知识、概念、生活经历等等,但实际上类似于感觉初级皮层的功能形成与意识可感知的记忆形成本质都是权重落实问题。只是大脑很难意识到初级皮层的感念,初级皮层的权重形成也是倾向于统计上的落实。而记忆更倾向于一次性的权重落实,和反复单一刺激强调的权重落实。所以无论是情景记忆、程序性记忆,还是陈述性记忆,都是不同类型的输入建立关联的过程而已。回想是记忆落实和加强的重要手段,例如恐怖性经历会刺激本能反复回想该记忆,从而会终身难忘。难忘的记忆征用了较多的记忆资源,并且时常回放进行巩固,轻描淡写的记忆动用了较少的记忆资源,又很少回想,这些记忆资源慢慢被其他记忆所替代。 Read more
智能时代得创业窗口期将变短,超级公司诞生得可能性巨大,但在通用智能技术达到临界点之前,一定程度上的领域细分依然是人工智能创业的主旋律,超过临界点之后,大多数竞争者将被淘汰,且越甩越远。
互联网时代还难以进入寡头垄断,整个三十年的创业期内各类互联网公司风起云涌,主要的原因是数据的产生和数据的结构化是个体力活,很多公司仅仅凭借数据生成(算法生成和人工生成)和数据结构化就能活得滋润,更不要说建立在数据之上的算法积累了,领先优势更巩固了互联网垂直创业者在各自行业得地位。
智能创业得变革机会要比互联网更多,因为不是所有得行业都需要互联网化,但所有得行业都会面临智能化,两者已经不是一个量级。
智能化的路径是专用向通用演变的过程,也是从众多垂直创业者向一家独大演变的过程。谁得到更通用的智能技术,谁就得到更进阶的密匙。
仅有互联网无法实现共产主义,只有人工智能才能实现终极生产力。
他到底是合伙人还是员工?
这是不同的概念,合伙人分的是股份,员工理论上只分期权,所以这个事件的本质是双方的角色分歧,CEO把他当员工看,他把自己当合伙人,而这个角色应该在创业开始时就应该说清楚。
如果你创业想找一个人给你出技术,那么你要分清楚一件事儿,你是让他帮你熬过创业初期还是持续管理公司,前者决定你必须找一个员工,后者才决定你找一个合伙人,合伙人分的是股份,这个股份的价值在于长期性的认可,直接给股份是十分高风险的事情,很多创始人耍机灵,开始时玩模糊战略,等过了两年看清楚了,再决定你的角色问题,就会出现分歧和纠纷。
期权和限制性股权的性质比较相似,都是依赖过去贡献的股权授予机制,是一种按劳分配对抗不确定性的优良机制,所以适用于公司的大部分员工,用于奖励员工过去的努力,注意到没有,这个事件里面就有一段话在讲这个问题,你过去的努力,我已经给我你分红,未来的得看你的表现,这就是对待员工的态度,如果你合伙人,是创始股东,大家就是兄弟,要坐在一起商量,性质是截然不同的,就算你已经不在公司了,你依然是股东,你依然可以享受公司的分红,就像上市公司的大众股东,谁也不同跑去给公司打工,不照样可以享受分红?这就是股权的威力,股权决定了你对公司的拥有权比例而且不用打工就可以获取相应收益的权利。
说到这里,顺便提一下代持,一种对普通员工分配具有无投票性质的股权的办法,这样既保持了管理层的控制力,也保证了大家的努力得到的应当的现金收益。
那么实际上还是有第三种人存在的,比如职业经理人,他既不是创始股东和创始团队的成员,但又是公司重要的管理团队成员,其实是半员工半合伙人性质,这样的人,一般情况下,可能会授予一定的股权,再授予一定的期权,给股权代表着我请你来,是把你当朋友,当兄弟,一起奋斗,给期权,代表着,我还是不是完全信任你,你还要通过表现拿剩下的部分。
但无论是怎样的角色定位,作为创始人都应该在决定与一个人一起共事时,就应该把这个事情理清楚,说清楚,期权是应对概率问题的重要手段,当你对对方的确心有顾忌的时候,就应该明确的说出来,对不起,我不能直接给你股权,我只能给你期权,有部分信任的时候,可以说,我可以给你1%的股权,剩下4%必须是期权,等等。
打马虎眼藏心眼的行为是不负责任的,严重的话就是诈骗。
所以总的来说,创始人首先应该理清楚目标人物的角色和不确定性问题,这样才能结合时间维度、贡献维度和控制维度,组合生成相应的股权期权方案。
为了让初学者花最少的钱办性价比最高的事情,我构造了这样一套DIY装机配置,在最大化利用显卡资源的同时,极力压缩无关配置。这个配置的主要特性是去掉了扩展性的可能,从而大幅降低了成本。
由于训练和推理主要使用显卡,显卡还是要尽量的好,为了能够训练主流的模型,我们还是要上性价比最高的NVIDIA 1080Ti。
显卡:技嘉(GIGABYTE) AORUS GTX 1080Ti,如果有渠道也可以买海外的英伟达出的公版(699美元)。
CPU:根据预算可以选择i5 7600K或i7 7700K,当然其他的LGA 1151接口的CPU都可以根据自己的经济能力进行选择,注意一下PCIe的通道数,只要要保证16通道,可以上英特尔官网查一下https://ark.intel.com/products。接口一定要是LGA 1151,后面的主板和他是配套的。
内存:至少16G,如果选择16G,建议两个8G,利用上双通道。如果32G,上两条16G。内存频率不是特别重要,DDR4 2133或2400普通的台式机内存就可以了。
主板:华硕Z270-A,跟X99系列主板的3000元起步,Z270要便宜好多,如果选择扩展性好的,比如网上经典的深度学习主机配置里那个三显卡支持的X99-E WS主板,X99系列主板的确有较好的扩展性,他需要搭配的CPU也要高端一些,起步CPU是6800K,比7700K要贵几百元,但6800K的优势是多核,主频却弱于7700K。对游戏、VR的支持,显然7700K更给力一些。Z270A+7700K京东有套装,便宜好几百块。
SSD:考虑到充分发挥显卡的性能,我们尽量不再占用PCIe通道,所以放弃了速度更快的m.2接口SSD,而选用了SATA3的SSD,但6Gbps的速度其实日常使用已经足够快了,而且SATA3的SSD可以持续达到6Gps的读写性能,而m.2(使用PCIe模式)或PCIe的SSD,在连续写入达到4Gb之后,写入速度就迅速衰减到1.6Gbps。推荐型号:三星(SAMSUNG) 850 EVO 250G SATA3 固态硬盘,容量根据需求自己选。
硬盘:建议还是要有一个上T的机械盘用来存数据的,这个就随便了,只要是SATA3接口的随便选。
电源:如果将来不再加显卡了,理论上这个配置也不适合加显卡,毕竟通道数只有16个,一个显卡占用的PCIe×16就给用没了,虽然这个主板支持两个PCIe×16插槽,但是真是两个都插上,主板芯片组就会变成两个8通道的运转了。所以600W的电源基本就够用了,建议电源要稳定,最好上EVGA品牌,大厂实力,然后根据经济能力自己选就好了。
虽然是深度学习的乞丐版,这个配置在游戏玩家中也算非常不错的高端配置了,玩各类游戏那是不在话下,再来个VR套装,就真是物尽其用了。
装机过程要注意的是显卡供电要求比较高,需要用两个电源线把两个供电口都插满。
如果有人使用这个配置装机了,你可以在此留言,我将再写一篇ubuntu、windows10双系统安装,以及深度学习基础环境搭建的文章。
Faster R-CNN是互怼完了的好基友一起合作出来的巅峰之作,本文翻译的比例比较小,主要因为本paper是前述paper的一个简单改进,方法清晰,想法自然。什么想法?就是把那个一直明明应该换掉却一直被几位大神挤牙膏般地拖着不换的选择性搜索算法,即区域推荐算法。在Fast R-CNN的基础上将区域推荐换成了神经网络,而且这个神经网络和Fast R-CNN的卷积网络一起复用,大大缩短了计算时间。同时mAP又上了一个台阶,我早就说过了,他们一定是在挤牙膏。
本文实现了Fast-RCNN主要部分的翻译工作,在SPPnet出来之后,同在微软的R-CNN的作者Ross迅速怼了回去,抛出了更快更好的Fast-RCNN,思路为之一新的是,将之前的多阶段训练合并成了单阶段训练,这次的工作简洁漂亮,相比之前的RCNN,怀疑作者是在挤牙膏。另外,面对灵活尺寸问题,Ross借鉴了空间金字塔的思路,使用了一层空间金字塔。